
Core Store
The purpose of this page is to describe a core facility for Reservoir, with the intention that the other facilities described here can be implemented in separately implemented plugins. Plugins provide a market mechanism, and give users a choice. But without a core provided by the identity provider / domain hoster, it will not work.
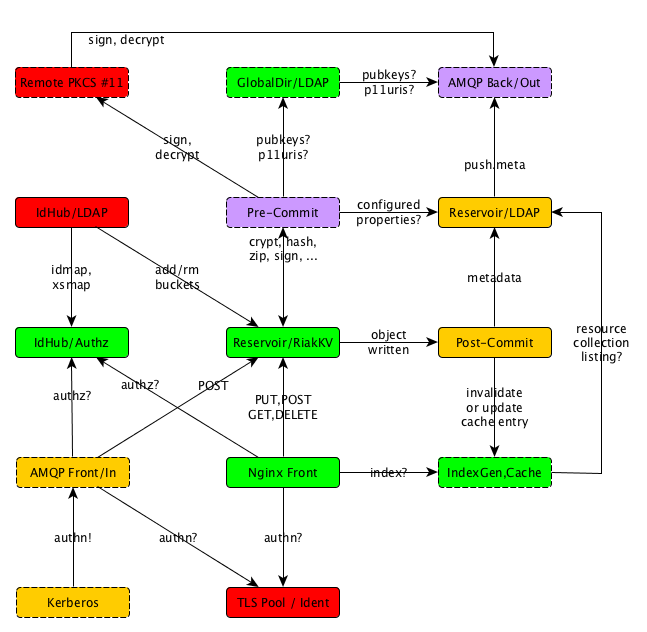
Object Store and Directory
One element that is of general use, is an Object Store with a RESTful API, capabile of granting access based on the usual Kerberos credentials. Our choice for this is currently Riak KV; this is a long-standing, proven solution and it has a long track record as an open source project. It does not waste any time on authentication or authorisation, so we can add all that using the approach to identity in the IdP of our InternetWide Architecture.
The metadata describing objects in the Object Store is stored in the Global Directory, and we use the term Reservoir as an indication of the combination of Object Store, Global Directory and all the rules and procedures for access control, queue management and so on.
As an exception, small objects may be stored directly in the Global Directory, using a ``data:`` URI instead of a URL pointing to the Object Store, in the interest of speedup and simplification. This could be useful for simple objects such as vCards and iCalendar entries.
The resulting model has relatively simple semantics, and can be easily understood by users; more importantly, the Reservoir becomes a highly generic component of the InternetWide Architecture. This provides ARPA2 projects with a foundation for a great variety of facilities, such as backup space. It is part of the task of the IdentityHub to allocate storage space on the Object Store to plugin services that require storage, as well as access to metadata stored in LDAP. Furthermore, a slightly more advanced level of service will be added to facilitate rotation of backup files.
Note the great value of having data storage facilities in the generic IdentityHub component; this facility ranges over all plugins, and so domain owners get to choose a quality level that applies to all the acquired plugins. Also, the ability of uploading to a central store means that processes such as backups can be automated, without any user interference, meaning that these backups actually are made.
Users may also create a storage partitions for personal use and for shared group use. Such partitions could be used to upload and share documents, music and so on; it fulfills the same needs as have led to the use of storage clouds, with the exception that it is now fully controlled by the end user.
Reservoir LDAP is Global Directory
The LDAP service offered as part of Reservoir is incorporated into the Global Directory over which the IdentityHub announces public credentials. This LDAP service has access protection so that, for example, contact data and document collections can be limited to an intended viewing/editing audience. This means that LDAP searches will only reveal those parts of the Reservoir to which an authenticated user is authorised access.
LDAP is not a database but a protocol, and precisely that makes it very useful for access over a network. Many applications are able to use it as a centrally-updated contact database (no more manual SIM copies) and perhaps even a shared storage space for notes alongside those contacts. And, of course, an internal LDAP is a very good source for once-looked-up entries in the Global Directory, including public credentials!
Passing data securely over AMQP
Most documents are passed over email these days. This is not a perfect solution — the extensions are much larger than their accompanying texts and clutter the mailbox, slowing down general access. This is agravated by documents being stored in various versions, and at some point nobody knows what the latest version is. Most importantly, the search for documents is uncertain, and their exchange is insecure.
AMQP is a protocol for message passing, which at first may sound a lot like email, but it is intended for automatic handling, unlike email which is primarily for human consumption. Automatic processes that reliably send documents need to filter what they welcome, so as to mitigate attacks and assaults. This can be achieved by requiring authentication, which is indeed a built-in facility of AMQP.
For the Reservoir, we intend to adopt the AMQP 1.0 standard as a means of exchanging messages between domains, always under strict cryptographic validation of originator identity, and passing along any metadata that is to be stored in the LDAP index. The actual messages that are passed end up in the Object Store.
The customary approach for AMQP is to deliver to one or more queues, and this does make sense here too; there can be input queues that are sorted by MIME-type (all videos in one place, ready for your media player) or originator (all email from a certain customer bundled for quick and separate review). Things found in the input queue can be relocated to a final destination in the internal Reservoir by its users. Similarly, output queues ship documents from the Object Store to the outside world, using AMQP or, when unavailable or less preferred by the recipient, perhaps over another protocol like XMPP or email.
So, how can a recipient express their preferences? Well, they already do that. They express email servers in MX records, and XMPP and AMQP in certain SRV records. All these have an ordering attribute, which is an integer with no absolute meaning but for preferences within the specification. What we can do with delivery over preferred channels is to look at all those settings as a whole, and sort delivery based on that. It will be somewhat random to non-compliant setups, but it is very easy to repair and not in any way problematic for the isolated services.
Structuring data with Resource Collections
The Reservoir is configured by each user or group to suit its needs; in general, a series of Input Queues and Output Queues can be created and services accessing the Reservoir make those available as a potential source or target for object movements.
The storage aspect of the Reservoir is structured through Resource Collections, where each individual object counts as a separate Resource. Resource Collections may include other Resource Collections as is seen fit, to facilitate shared data.
Each Resource Collection automatically has an owner, but it can also have typing information. For Input Queues Output Queues, typing information is useful to know what information can pass through.
Information kept in a Resource Collection is considered an implementation of the hunter / gatherer mode of Internet use that we consider to be a major usage pattern. It is possible for every welcomed Identity to access a Resource Collection for reading and/or writing. This means that objects may be added and removed, acting on a Resource Collection that may be personally controlled, or shared by a group.
Note how this model agressively redefines usage patterns, especially for collaborating groups; the Reservoir enables groups to gather documents, modify and share them, without a need to send emails with new versions. This mechanism is meant to provide a good basis for groupware tools, such as collaborative document editing.
Integration with Office Tools (future)
As an ongoing quest, we are looking for integration between online activities and office tools. For example, form painters that interface with a database and couple back to spreadsheets might be very interesting. Although OpenOffice.org offers a few such tool fragments, it does not seem to have reached a final state.
SQL on its own is perhaps too technical, and it is usually encapsulated as part of a plugin, rahter than centrally stored. On the other hand, central databases have the advantage of always being up to date, unlike backups which may lag behind some bit.
In theory, one should be able to import database tables into spreadsheets, as well as paint forms with products like LibreOffice Base. In practice, this is ill-documented and it does not work reliably. When work is done in this area, we start to see a stronger usecase for a database. We would choose PostgreSQL for reasons of stability, performance and mature replication.
It may be possible to use an ODBC driver for LDAP, even if open source drivers do not seem to exist at this time, to integrate with such desktop tools. As indicated, there is a lot of work that has not been done yet in this area, but it is good to have room to grow.